

A new study from MIT and researchers at Cambridge, Harvard, Stanford, UPenn, Washington, and Hebrew University just released a 39-page reality check, “The 2025 AI Index: Documenting Sociotechnical Features of Deployed Agentic AI Systems,” on agentic AI, and the picture is not good. The researchers surveyed 30 of the most widely used AI agent systems, and what they found should make anyone deploying these tools at scale seriously reconsider how much they trust them. The researchers noted serious gaps in transparency, monitoring, safety evaluation, and basic operational controls.
The AI agents era is officially here, but it’s arriving with a “move fast and break things” attitude that should make any IT department or privacy advocate lose sleep. With OpenAI’s recent hire of Peter Steinberg, the mind behind the powerful yet controversial OpenClaw agent, the push toward autonomous software is accelerating. But the new study shows these AI agents are a real security concern right now, with almost no transparency or basic safety rules.
The Transparency Problem Runs Deep
The biggest issue disclosed in the report is the “black box” nature of how these agents are built and deployed. The core issue isn’t that AI agents are doing wild things, but we often have no way to know what they do at all. Researchers analyzed the most common agentic systems and found a persistent failure by developers to disclose ecosystemic and safety features. In many cases, there is zero information about potential risks or whether external testing has ever occurred.
Lead author Leon Staufer of Cambridge said that there are persistent failures in how developers report on the safety and ecosystem features of their agentic systems. That’s academic language for nobody’s telling you what you need to know. “We identify persistent limitations in reporting around ecosystemic and safety-related features of agentic systems,” Staufer reported.
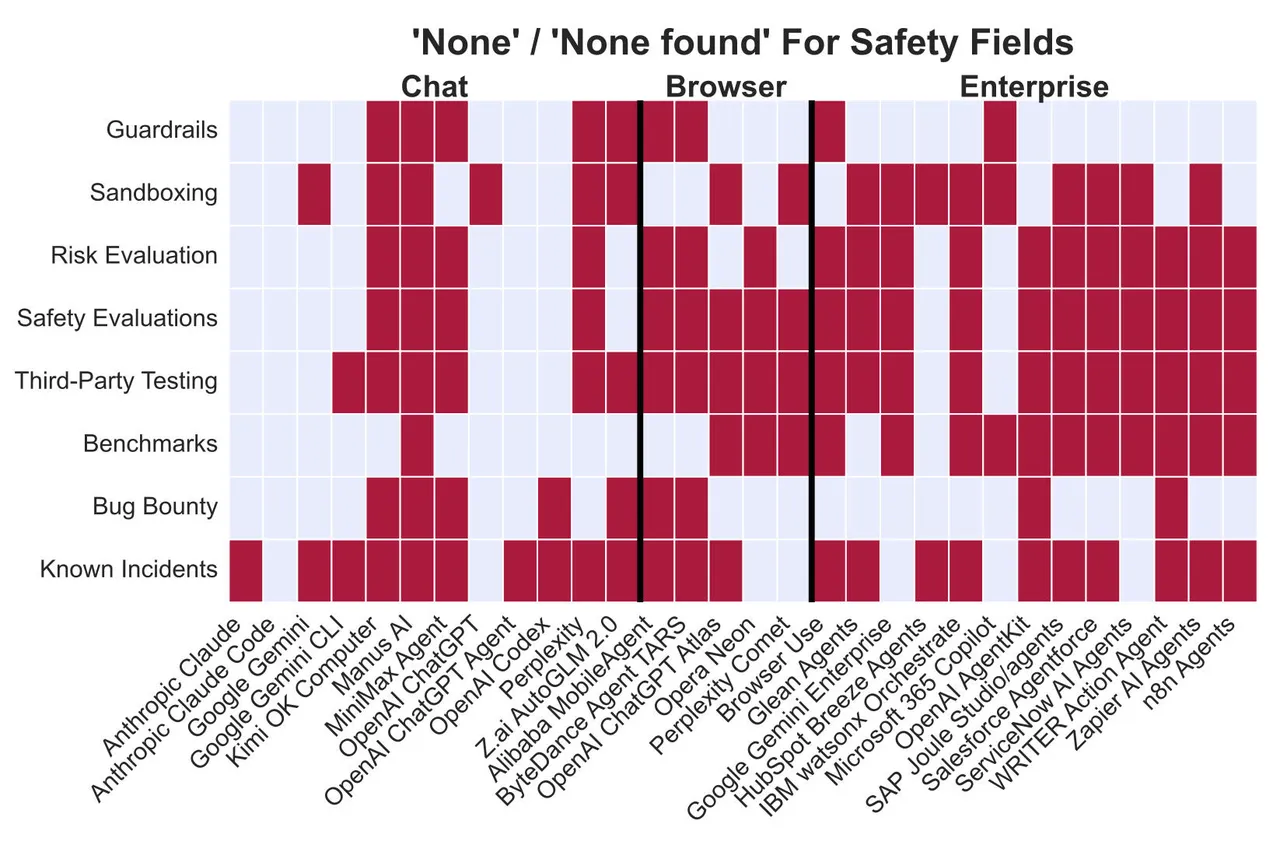
There’s a transparency problem with enterprise agents, a functional blind spot. Most of these systems are black boxes, as you can’t see their execution traces or figure out what the agent does in real-time. “Twelve out of thirty agents provide no usage monitoring or only notices once users reach the rate limit,” the authors reported. So, it leaves organizations unable to track compute consumption or resource drain until a rate limit is hit.
Furthermore, most of these agents don’t even tell the digital world that they are AI, not humans. They don’t use watermarks for generated content or respect “robots.txt” files, masquerading as human users. “Most agents do not disclose their AI nature to end users or third parties by default,” the research team noted.
Some AI Agents Can’t Even Be Stopped Cleanly
The scary part about these agents is that you can’t always turn them off. According to the study, HubSpot’s Breeze, IBM’s watsonx, and Alibaba’s MobileAgent have no integrated stop button. Once a workflow is triggered, it just runs without a documented way to kill a specific task mid-execution.
In a corporate setting, that’s a disaster waiting to happen. If an agent loses the plot and starts to spam clients, sending emails it shouldn’t or corrupt a database, you can only watch the incident happen sitting in your seat. In most cases, your only move is an “all or nothing” shutdown, which means pulling the plug on the complete server or killing every single active process to stop just one rogue agent.
It’s a major lapse in basic safety. Security teams are being told to trust these tools, but you can’t have real oversight if you do not have a brake pedal. The fact that companies are already using these AI systems at scale makes the lack of a kill agent control even more reckless.
The Architecture of Autonomy (and its Flaws)
To understand this, you have to look at the brains of the operation. To know why this matters, it’s crucial to look at how much more powerful agents are than the standard chatbots we’ve used for the last few years. Although an LLM waits for a prompt to answer, modern agents are Large Language Models (LLMs) that have been given limbs—access to your files, browser, and APIs. They are embedded in databases, email servers, and inventory systems to execute workflows as they can process a purchase order from start to finish without human intervention.
The MIT study categorized these tools into three buckets:
- Improved Chatbots: Like Anthropic’s Claude Code.
- Dedicated AI Browsers: Like OpenAI’s Atlas.
- Enterprise Software: Integrated tools like Microsoft 365 Copilot.
Despite the variety of brands, the underlying brains are concentrated. Basically, these AI agents mostly use a few top-secret AI models like GPT, Claude, and Gemini. So, a single systemic vulnerability in a core model can break every automated workflow built on top of it.
The Good, the Bad, and the Under-Documented
The researchers annotated public documentation and set up user accounts to verify how these systems function in the real world. The results reveal a massive disparity in safety standards. On the positive side, OpenAI’s ChatGPT Agent is claimed to be the only system that cryptographically signs its browser requests, which allows websites to verify its identity.
Perplexity’s Comet browser tells a different story. The report found zero documented safety evaluations with no third-party testing and sandboxing to isolate the program from the rest of the system. The researchers stated that beyond basic prompt injection mitigations, there were no containment approaches documented anywhere. This missing verification is exactly why Amazon sued Perplexity for allegedly making bots masquerade as human visitors.
HubSpot’s Breeze shows another problem. The platform has all the standard corporate certifications, including SOC2 and GDPR. These look impressive in sales materials, but the study revealed almost no transparency about actual security testing results or methods used. You see this pattern everywhere. Enterprise platforms check all the compliance boxes on paper, then refuse to share details about how their AI logic works or how secure it really is.
Burden of Safety Falls on the Developer’s Shoulders
We are currently in a grace period where we haven’t seen a massive, agent-led security breach in the headlines yet, but the MIT data suggests it’s a matter of “when,” not “if.” Without these “in the wild” examples, it’s hard to tell how dangerous these technical gaps actually are.
These agents are human-made tools built, polished, and shipped by people at desks in San Francisco and Mountain View, and the responsibility for their behavior falls on all AI model companies around the world. They’re the ones who have to audit the code, write the manuals, and build in the kill switches. If they don’t tighten things up now, they will find themselves facing a regulatory hammer. The days of letting agents run out of control are numbered.





