

Anthropic has released Claude Sonnet 4.5, and the company is calling it “the best AI model in the world” for coding, building autonomous agents, and general computer use. And while that kind of claim usually makes me raise an eyebrow, this one actually has the benchmarks and some early real-world wins to back it up. Anthropic further claims it as the “strongest model for building complex agents” and for “using computers.”
The headliner here is how much more capable Sonnet 4.5 is at long-running, complex work. Anthropic says it can keep its head straight on a single multistep project for over 30 hours. That’s a big leap from earlier versions, which usually drift or collapse after a handful of hours. For coders, that means more than just answering syntax questions with new model’s ability to manage entire software builds, refactor large codebases, and stick with a task in ways earlier models couldn’t.
New Features Alongside Sonnet 4.5
Sonnet 4.5 also introduces features for developers including checkpoints (so you can roll back when things go sideways), native code execution, and file creation straight from your AI chat. If you need a spreadsheet or a presentation whipped up while you’re testing scripts, Claude can now spin that out without breaking stride. Anthropic also reworked the Claude Code terminal and released a VS Code extension because that’s the IDE that developers use the most.
On the agent front, Sonnet 4.5 is modeled to run longer, smarter, and with better memory. With the new Agent SDK, developers can create their own AI agents that juggle permissions, use subagents for side tasks, and generally act more like autonomous coworkers than chatbots. That’s where the “real-world agents” claim comes into play, and if the 30+ hours of autonomous coding some companies report is accurate, this could reset expectations across the industry.
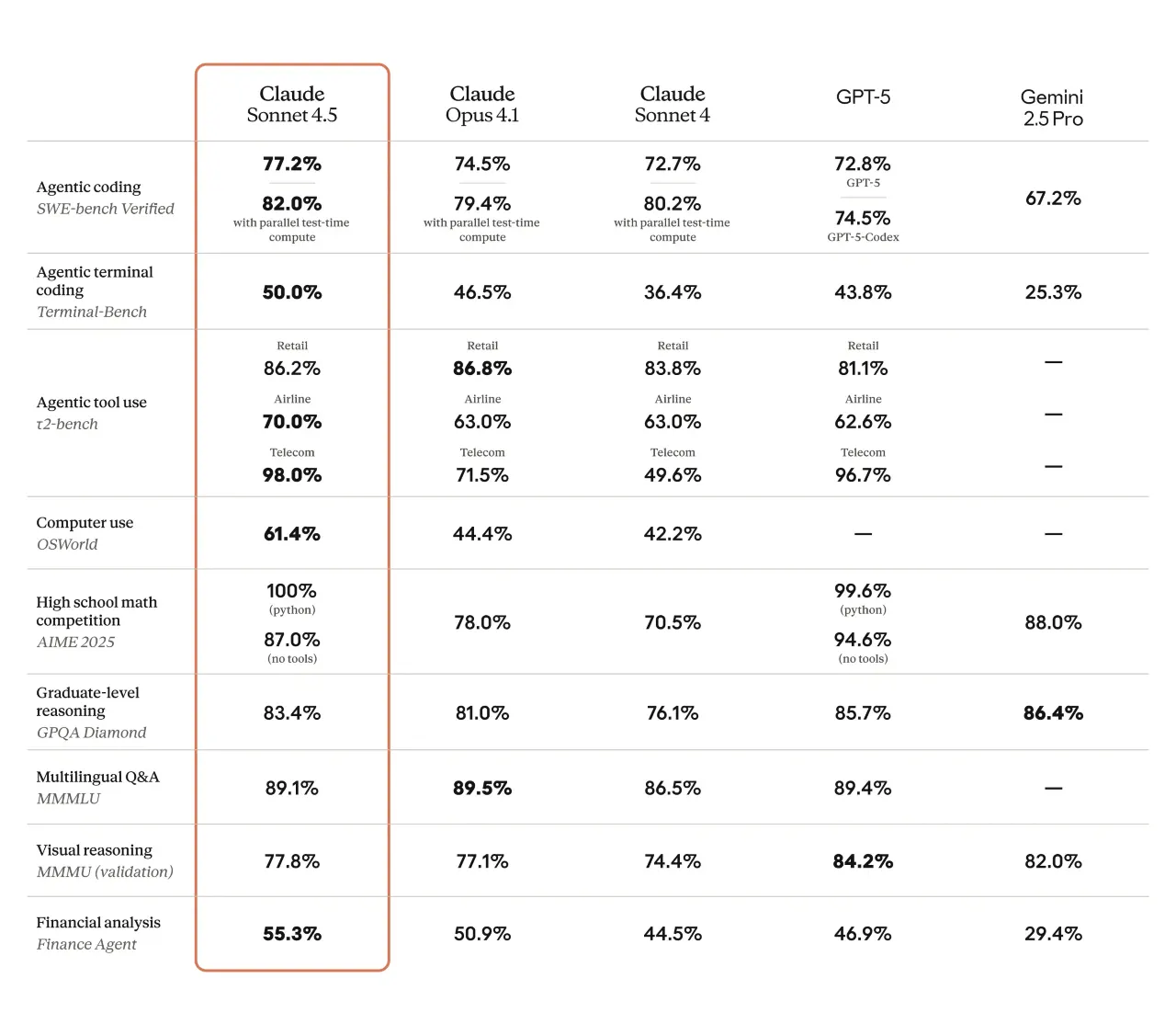
Benchmark data helps to see what’s new in the model and how strong it is in different scenarios. On SWE-bench Verified, which tests real-world software engineering tasks, Sonnet 4.5 scored 77.2%. That puts it ahead of OpenAI’s GPT-5 Codex (74.5%) and Google’s Gemini 2.5 Pro (67.2%). In OSWorld, which evaluates how well AI handles actual computer interactions, it increased from 42.2% in the last release to 61.4%, a major leap in just four months.
Anthropic has also emphasized alignment improvements. The company claims Sonnet 4.5 is less likely to fall into habits like excessive agreement, misleading answers, or power-seeking behavior. These may sound abstract, but for anyone relying on an AI system in production, fewer behavioral quirks translate into less babysitting and more trust in outputs.
The pricing structure remains unchanged from Sonnet 4: $3 per million input tokens and $15 per million output tokens. That stability, combined with the performance jump, makes the upgrade a better deal for businesses already lean on Claude for their projects.
Claude Sonnet 4.5 is available now through Anthropic’s API and apps.




?")
